Database Replication: Master-Slave Replication Architecture

I am a highly motivated and experienced engineer with a passion for helping teams deliver software faster, more reliably, and more securely. I am proficient in a wide range of DevOps technologies along with Software Development and have a proven track record of success in leading and mentoring teams. I am also a strong communicator and educator, and I enjoy sharing my knowledge with others.
Recently I have started writing about database replication, In the first article I have explained the need for database replication if you have not read yet, I recommend you to read Need for Database Replication before continuing this. We will discuss Master-Slave replication architecture in this article.
Master-Slave architecture also called Active-Passive or Active-Standby or Leader based replication architecture
The database request can be two types such as,
- Write request (Insertion, deletion, and updation)
- Read request
Note: I replaced all words slave with replica since it can be considered as offensive :p
Simple Master-Replica Architecture
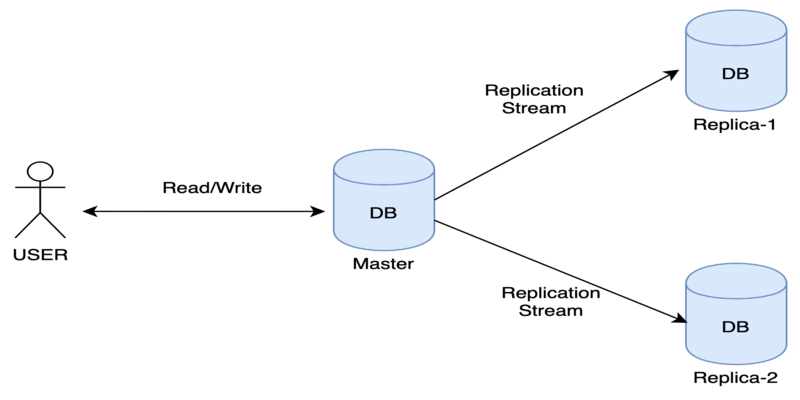
Above diagram is the simple master-replica architecture contains one master and two replicas
Basically master replicates the database into multiple copies(also called replicas) through the replication stream.
All read/write request goes to the master. If any data changes happen in the master those changes will be streamed to replicas as well so master and replicas are in sync always. the lag between master and replica is called replication lag
Avoid downtime using replicas
Since all request goes to master then what is the use of these replicas? What happens when our master goes down for some reason then our application also will go down because there is no master to handles requests.
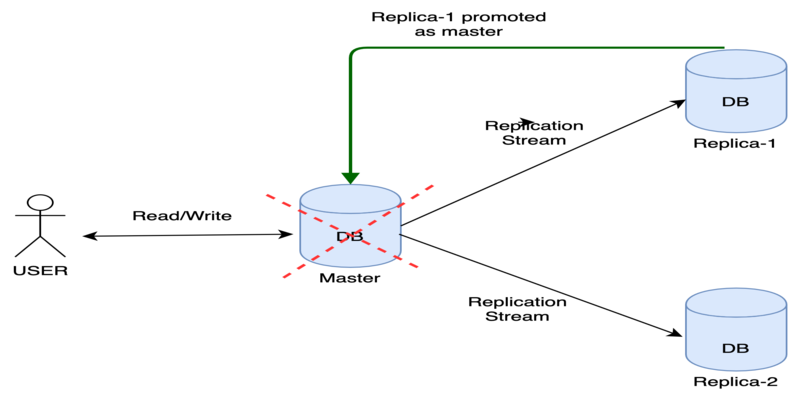
Using replicas we can avoid this. When the master goes down. there will be an election between replicas and one replica will be elected as leader and replace the dead master. as you can see in the above example since the master is dead replica-1 is elected as the new master.
In this way, replicas can be used to achieve high availability database.
Improve performance using replicas
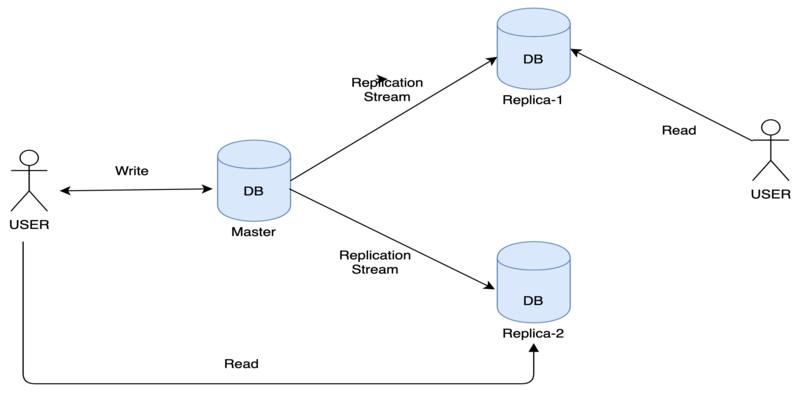
We can also significantly improve the performance of our database by
Redirecting all read requests to replicas
Redirect only write requests to master
previously master handles both read and write but now we bifurcated the requests among master and replicas. this kind of architecture balances the load on our database server. In our example diagram, there are only two replicas but in actual application, it can be more as 100s of replicas based on application load so the read requests even more divided among replicas.
Now let say master goes down for some reason. now only our write requests will go down till master switch happens and users can still do the read requests so this will not be a single point of failure.
as said above even master goes down immediately the master switch will happen so there will be very little downtime for write requests.
also, we can tell our application to select the nearest replicas based on geographical locations for reading requests so network latency will be improved drastically.
In the next article, we will discuss how synchronization happens between master and replicas.



